




数学领域欺诈性出版
2025-09-15
Ilka Agricola, Lynn Heller, Wil Schilders, Moritz Schubotz, Peter Taylor, and Luis Vega
1 引言
本报告是国际数学联盟(International Mathematical Union, IMU)与国际工业与应用数学联合会(International Council of Industrial and Applied Mathematics, ICIAM)联合工作组的两份出版物中的第一份。我们将在此分析数学科学领域的出版现状,并系统阐述由此产生的各类问题。该系列的第二篇出版物[43]将面向研究人员、政策制定者及数学研究评估人员,提供具体建议、操作指南与最佳实践方案。它将详细阐释如何识别并应对那些试图操纵文献计量指标的行为,从而帮助学术界重新掌握科研评价的主动权,并推动必要的改革。
作为学生、教师、作者、审稿人、编辑以及各类委员会成员,我们共同参与了科研成果的创造、出版、传播和评价。在当前的学术环境中,科研质量的评估在很大程度上受到文献计量分析的影响。这使研究人员有着强烈的动机去优化自己的文献计量数据。遗憾的是,越来越多的人正通过欺诈手段达成此目的。诸如论文工厂(paper mills)、掠夺性期刊(predatory journals)和引用联盟(citation cartels)等新兴(且对许多人仍陌生的)威胁,正持续侵入科学出版的“生态系统”,危及我们行业的诚信。
附录A提供了详细的术语表,并列出了大量可供延伸阅读的参考文献,以佐证文中观点。我们推荐优秀的著作[5]作为主要参考资料。需要特别指出的是,参考文献中大多数文章发表于最近五年,反映出该问题的紧迫性。
显然,我们所述问题背后的两大驱动因素为:第一,开放获取(Open Access)作为一种科学出版商业模式所带来的论文处理费(Article Processing Charges, APCs);第二,对量化研究产出评估的普遍需求。此外,那些收集引用数据并用其生成诸如期刊影响因子(journal impact factor)、h指数(h-index)以及由此衍生的“高被引学者”(Highly Cited Researchers, HCRs)名单的公司,也深度参与了这一体系。我们将论证,此类产品正对学术出版事业产生有害影响。
本文仅包含部分最重要的参考文献。完整且可点击参考文献的版本请参见arXiv [2]。
2 数学科学中的文献计量学
“当度量成为目标时,它就不再是一个好的度量。”——英国经济学家 Charles Goodhart(1975)
2009 年,Adler、Ewing 和 Taylor 分别受数学统计学会(Institute of Mathematical Statistics, IMS)、国际数学联盟(IMU)以及国际工业与应用数学联合会(ICIAM)的委托,调查研究定量评估对其学科产生的影响。他们被要求完成的任务是:
学术界对透明度和问责制的追求催生了一种'数字文化',机构和个人相信通过某些统计数据的算法评估就能做出公平决策;由于无法衡量质量(最终目标),决策者便用可量化的数字替代质量。这一趋势需要专业'与数字打交道'的数学家和统计学家发表见解。
最终的成果是报告 [1],并在多个平台上发表。虽然这份报告至今仍具有高度相关性,但新出现的现象值得进行类似讨论,即对量化指标的普遍操纵。为提供背景,本节将简要回顾[1]及其他论文[12,24]对数学科学出版文化的论述,并提出若干问题以激发读者思考。
2.1 数学家的出版方式
与其他学科相比,数学家通常发表的论文数量更少,合作者和被引频次也偏低。这使得单纯基于文献计量指标来比较数学家与其他学科的科学家缺乏意义。我们的观察是,文献计量分析的支持者大多理解这一点:他们通常承认学科背景的重要性。
但较少被理解的是,不同的数学分支之间也可能存在非常不同的引用文化。再者,由于数学学科的引用习惯所导致的绝对引用数偏小,也让人质疑,是否能从背景噪音中分辨出任何“质量”的信号。对我们而言,难题在于:文献计量学在多大程度上与数学科学研究评价相关。例如:
Q1: 在数学科学中,一篇论文如果被引用次数相对较多,是否意味着它比另一篇更好?
Q2: 数学科学期刊的影响因子是否能反映其质量?
Q3: 在数学科学中,研究者发表的论文数量相对较多,是否意味着他比另一位研究者更优秀?
Q4: 是否应该使用特定时期的引文分析来评估数学科学家的职业生涯?
Q5: 是否应当利用汇总的引文数据来对数学科学机构进行排名?
Q6: 文献计量指标的存在是否会影响研究人员的行为?这种影响是正面还是负面?
当前讨论的关键在于:数学领域引用总量偏小的学科特性,使得该学科尤其容易受到文献计量操纵的影响。基于此,我们在下文将论证对Q6的答案是肯定的,且这种影响总体上是负面的。具体来说,有充分证据表明,一些个人、研究群体、机构和期刊编辑委员会正在合谋,通过调整出版行为来操纵基于文献计量分析的排名。
2.2 文献计量学
引文数据库最初是作为一种研究工具建立的,旨在通过列出引用某篇(通常具有开创性的)论文的文献,帮助学者检索学术文献。这一活动的历史可以追溯到 20 世纪初 [23]。然而,普遍认为,现代意义上的文献计量分析起源于 Garfield 在 1950 和 1960 年代的工作 [39]。
这项本值得称道的事业逐渐演变为以科研定量评估为主要目标的体系,其发展历程可见于多部文献——其中包括主要引文数据提供商科睿唯安(Clarivate)的长期员工戴维·彭德尔伯里(David Pendlebury)所著的[32],其他论述参见[23]和[17]。正如 Goodhart 在本节开篇引文中所暗示的,当被衡量的活动涉及人类行为的某些方面时,就会有巨大的动机去操纵这一体系。我们看到,在所有学科的文献计量学领域,这种情况正在发生。例如,Macdonald 和 Kam 的论文 [27] 就专门讨论了基于文献计量学的科研评估体系的脆弱性。由于前述原因,这种影响在数学科学中尤为恶劣。目前,人们仍在努力开发不易被操纵的指标,但迄今为止尚未有任何指标对现状产生实质影响。
2.3 学术出版生态系统
我们先简要看一下学术出版生态系统的简化版本,如图 1 所示。毫无疑问,所有研究的中心是个体研究人员。他们供职于大学或其他研究机构,这些机构可能是公立的,也可能是私立的。这些机构又会受到政府、部委、资助机构等权威部门的某种形式的评估或考核。研究人员在期刊上发表成果,同时他们中的许多人也担任这些期刊的编辑和审稿人。
期刊,顾名思义,是由出版商出版的。这些出版商有的是学术学会或其他非营利组织,但越来越多的则是利润丰厚的商业公司。为简化起见,我们在图 1 中省略了学会与学术会议,因为它们通常不是我们所要讨论问题的根源。
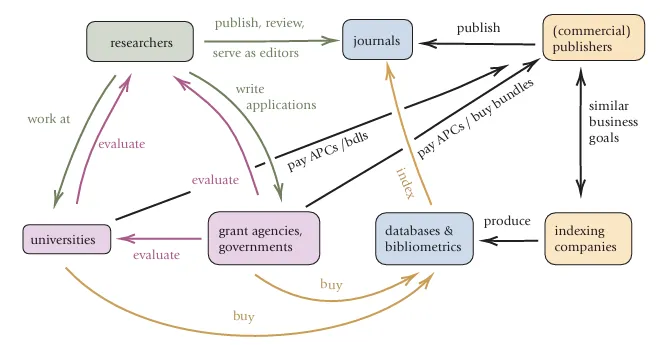
在开放获取(Open Access, OA)出现之前,上述就是主要的参与者。大学图书馆会根据研究人员的推荐订阅单本期刊,这种机制限制了低质量期刊进入馆藏的数量。随着数字化、开放获取以及科学共同体的不断壮大,经过漫长演变,新的问题随不同的视角出现:
对研究人员而言: 如何找到合适的研究发表平台,并提高自己工作的可见度?
对政府与资助机构的政策制定者而言: 如何量化科研评价?
对商业出版商而言: 如何创造(更多)收益?
大型出版集团的第一个决策,是推动整包期刊的销售,而不是单本期刊的订阅。其优势显而易见:只要整包里包含了某一领域的核心期刊,单个期刊的质量就不那么重要了,同时还能确保持续的收入,因为不再可能只取消某一本期刊的订阅。这正是 Springer Nature 和 Elsevier 的策略,而它们目前约占 zbMathOpen [42] 收录数学论文的 40%。
开放获取的出现,又引入了作者向期刊支付论文处理费(APCs)以发表论文的模式,这使得期刊有了尽可能多发表文章的动力。
引文索引公司及其数据库,原本只是为帮助研究人员发现相关论文而存在。但科研评价的定量化,使得它们的数据库和文献计量产品变得极其有价值。它们把这些产品出售给大型机构,声称能够实现客观的科研评价。
在文献计量学中,分析之所以可能,是因为存在这样的数据库:对一个足够大的论文集合 S,记录其中每篇论文 x∈S 所引用的文献集合 C(x)。在此基础上,期刊影响因子(impact factor)、作者的引用次数或 h 指数、某一领域的高被引学者名单(HCRs),乃至更复杂的统计量(如期刊排名或作者的经验引用分布)等指标,就成为一种计算任务。由于数据库特性会显著影响计算结果,我们需对重要引文数据库作简要说明:
Clarivate(2008 年前称为 Thomson Scientific)是一家英美合资的上市分析公司,员工超过 1 万人,2022 年收入达 26.6 亿美元。它负责计算期刊影响因子,并编制下文将要讨论的高被引学者名单(HCRs)。这些内容通过其付费平台 Web of Science (WoS) 提供。每年,Clarivate 都会基于其 Science Citation Index Expanded (SCIE) 数据库发布付费的期刊排名 Journal Citation Reports (JCR)。被收录的期刊列表并不公开(这一点本身就颇具问题),但每年被剔除的期刊数量极少,这说明许多掠夺性期刊和低质量的大规模期刊依然留在数据库中 [7]。通常来说,只要某个期刊有影响因子,它就会出现在 WoS 中。
Scopus 是荷兰出版公司 Elsevier 的产品。它提供期刊、论文和作者的各类指标,以及研究人员档案与分析服务。作为一家大型出版公司的文献计量部门,是否存在利益冲突的问题显然不可避免。Scopus 的数据库中被指存在可疑期刊 [16, 26]。它被用于计算商业化的期刊排名 SJR (SCImago Journal Rank)。快速分析 2023 年 SJR 在“数学”这一大类下的期刊显示,其中大约 20% 的 Q1 和 Q2 期刊并未被 zbMATH Open 收录——原因包括:它们与数学关系不大、质量低劣、或者被错误地归类为数学期刊。
Google Scholar 是 Google 搜索引擎中专门针对学术文献的部分。但它也会计算并发布指标。Google Scholar 常被批评缺乏对收录内容的控制,常见问题包括同一篇文章的重复记录。近期一项研究 [25] 显示,Google Scholar 的引文数据极易被操纵。
zbMATH Open 是一个免费的数学文献与软件的摘要和评审服务,由欧洲数学学会与 FIZ Karlsruhe 编辑。其索引政策是:收录所有可获得的已出版并经同行评审的文章、书籍、会议论文集,以及符合数学学科分类(MSC, Mathematics Subject Classification)范围的其他出版形式(例如 ArXiv 预印本),前提是其展现出真正新的数学视角。
Mathematical Reviews 提供的服务与 zbMATH 类似(不包括软件和预印本),由美国数学学会出版,是数学界同样高度认可的工具。Mathematical Reviews 与 zbMATH Open 目前共同覆盖约 1600 种期刊(以及许多老期刊与丛书),共索引约 500 万条文献。
ArXiv 是由康奈尔大学提供的服务,并获得其他机构部分支持。它是一个预印本库,包含近 240 万篇物理学、数学与计算机科学(以及其他少数学科)的学术论文。“把论文上传到 ArXiv” 对许多数学科学研究者而言是发表前的第一步,且其中可找到大量重要研究成果。
ORCID 是一个全球性的非营利组织,提供唯一且持久的研究者标识符,用于科研、学术和创新活动。这种标识符是解决作者身份歧义的有用工具。ORCID 拥有一套我们支持的核心创立原则。但需要关注的是,ORCID 与前文提到的商业数据库之间的关系。我们已经注意到,在某些情况下(例如登录过程中),原本的 ORCID 标识符被替换成了由这些商业公司控制的标识符。
3 2023 年 Clarivate 排除事件
3.1 Clarivate 的排除决定
2023 年 11 月,Clarivate 宣布在最新版的高被引学者(Highly Cited Researchers, HCRs)名单中,完全排除了数学这一领域。在说明这一决定时,它写道 [33]:
数学是一个高度碎片化的研究领域,每个专业方向仅有少数研究者深耕。该学科的平均发文率和被引率相对较低,因此发文量和被引次数的微小波动就可能导致整个领域的统计呈现与分析结果失真。正因如此,数学领域更容易受到通过操纵发文和引用来提升学术地位与获取回报的策略影响。
我们同意这一说法。看到一家专门提供引文数据的公司明确承认这些数据容易受到“优化地位和回报”的操纵,颇具意味。
有学者 [14] 认为,排除发生的原因是:在紧邻的前几年名单中,被列为 HCR 的许多人,在科学共同体看来并非顶尖数学家(更多关于该排除事件的细节见 [35])。相反,他们似乎是通过操纵自己的文献计量参数而进入榜单的,而这种情况最终已无法被忽视。表 1 给出了 2019 年数学科学领域 HCR 的主要机构隶属情况。需要注意的是,榜首的中国台湾中国医科大学(China Medical University Taiwan)并没有数学相关的学术项目。2024 年 11 月公布的名单中,数学依旧被排除,但未再作进一步说明。
在一篇博文 [34] 中,Clarivate 研究分析部主管 David Pendlebury 承认,他们因诚信问题排除了 2000 多人(这一表述相当含糊)。剩下的 6636 人被列为 HCR,但其中 48% 并未与任何特定研究领域对应(而是被标注为“跨领域 cross-field”)。至少有一位在 2024 年被列为跨领域 HCR 的研究者——J. A. Tenreiro Machado——实际上在 2021 年就已去世,这进一步引发了对底层数据质量的质疑。一项关于 HCR 的最新研究 [15] 指出,这份名单(不仅限于数学,而是整体)在 2019–2023 年进入了一个新的“阶段”:“这一阶段的特点是越来越多的学者档案被怀疑存在科研不端行为,这对名单识别真正有影响力的研究人员的能力构成了挑战。”
长期以来,人们已经论证 [1],常用的文献计量指标并不适用于数学科学,甚至可能不适用于整个科学体系。无论如何看待 Clarivate 排除数学的动机,其发生都迫使更广泛的数学共同体不得不关注这一现象。
3.2 其他学科的简要情况
我们不应从科睿唯安的决定中错误推断数学已成为被学术欺诈渗透的可疑学科。欺诈性科学同样发生在其他领域,而且不仅限于操纵文献计量指标,还包括伪造科研结果。事实上,在更广泛的科学领域中,后一种情况更为常见,因为这些学科的研究论文往往报告实验、实地调研或调查的结果,而这些结果必须依赖信任。实验科学中大规模数据造假的案例通常会被媒体广泛报道,因此也最容易进入公众视野。例如,2023 年 8 月,斯坦福大学前校长、神经科学家 Marc Tessier-Lavigne 因争议事件辞职 [31]。
总体而言,像生命科学这样的研究共同体,其规模远大于数学界,再加上为获得巨额资助而激烈竞争,因此出现更多问题论文并不令人意外。多项研究支持这一点 [8]。例如,2020 年一项关于神经科学领域撤稿论文的研究 [11] 得出结论:“源自论文工厂的撤稿论文正日益增加,这对科研共同体构成了严重问题。”
系统性的欺诈出版研究虽然稀少,但若把大量事件结合起来看,就能发现典型模式和总体图景。例如,过去两年,西班牙科学界经历了多起丑闻,详见《国家报》(El País)国际版的报道。萨拉曼卡大学前校长、计算机科学家 Juan Manuel Corchado,曾是一个极具规模的引文联盟的核心人物。他目前已有前所未有的 75 篇论文被撤稿。据称,西班牙一些最具产出的学者曾从论文工厂购买论文,而一些沙特大学则支付西班牙科学家谎报主要隶属。表1 中排名第二的阿卜杜勒阿齐兹国王大学(King Abdulaziz University)就是其中之一。类似的丑闻也在其他国家被报道,包括(按字母顺序):加拿大、中国、匈牙利、印度、波兰和越南。
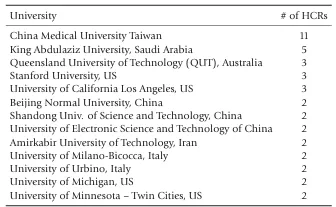
表1. 2019年数学领域拥有多位主要隶属HCR学者的机构(总数89人)
系统性研究的罕见例外之一,是德国《南德意志报》(Süddeutsche Zeitung)及公共广播机构 NDR、WDR 在 2018 年进行的一项深入调查。
总之,欺诈性出版是全球所有科学领域面临的重大问题,涉及不同资历的研究人员和各种研究环境。
3.3 极端案例:高被引学者与撤稿——以及它们的相关性
更深入地观察数学领域的 HCR(高被引学者)。2019 年,共有 89 位研究人员被列为数学领域的 HCR。2021 年,时任 Mathematical Reviews 执行主编的 Edward Dunne 对这些学者进行了深入调查 [19],因此我们的分析也基于同一年。首先,让我们总结一下 Dunne 的发现:
研究领域分布不具代表性。 这些 HCR 所从事的领域并不能代表整个数学科学。例如,没有人从事几何或代数方向,而在 60 个(可能的)数学学科门类中,只有 16 个(约 26%)出现在他们大多数论文的主要学科分类中。
HCR最常见的研究方向。 HCR 的主要研究领域包括:偏微分方程或常微分方程(37%)、统计学(16%)、数值分析(15%)、算子理论(10%)。
与数学大奖获得者重叠度极低。 如果不只看引用数,而是用主要数学奖项作为学术影响力的指标(Dunne 所考虑的包括由 AMS、SIAM、EMS 和 IMU 颁发的奖项,包括菲尔兹奖),那么在 2019 年的 HCR 中,只有 5 人获得过这些奖项。HCR 名单与获奖者名单几乎没有重叠,而历年来共有 29 个奖项、636 位获奖者。
奖项覆盖面更广。 数学奖项得主的研究主题覆盖约 61% 的数学学科,而不是集中在分析与应用方向。他们的常见研究领域(如代数几何和数论)在 HCR 名单中完全没有出现。
评价方式完全不同。 HCR 完全依赖于一个庞大且未经甄别的期刊列表上的绝对引用次数;而奖项则是由学会任命的评审委员会评选产生。
此外,Dunne 发现了明显不同的引用模式。为了解释这一点,我们引入两个相似但至关重要的指标(另见 [30] 以及 [19] 中对其的批评):
自引分数(Self-citing score, SCS): 表示某位作者的全部论文中,被引用的部分来自该作者自己其他论文的比例。换句话说:某位作者的论文获得的引用中,有多少来自他自己的论文?
自我引用分数(Self-referencing score, SRS): 表示某位作者的论文参考文献中,引用自己先前论文的比例。换句话说:某位作者的论文参考文献中,有多少是引用他自己的工作?
【译注:SCS 是“别人引用你”中有多少是你自己,SRS 是“你引用别人”中有多少是引用你自己。】
在计算这些指标时必须谨慎。从方法论角度看,只考虑 2000 年之后获奖的数学奖项得主才合理且必要(部分老获奖者已退休多年,不再发表论文;早期的引文数据往往不完整,而且引用模式可能随时间而变)。符合这一条件的数学家共有 365 位。作为第三个对比群体,Dunne 与 Mathematical Reviews IT 团队还基于 MR 数据库,确定了 2010–2020 年发表论文中被引用次数排名前 1000 的数学家 [19]。
差异非常显著,见表 2。虽然被引次数排名前 1000 的数学家的中位 SCS 与数学奖项得主相近,但 HCR 的 SCS 却超过两者的两倍。对于中位 SRS,也出现了同样的情况。尤其值得注意的是,数学奖项得主在后续工作中引用自己的比例非常低(SRS 仅 0.22)。
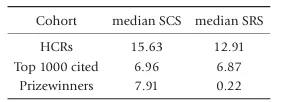
表2. 不同数学家群体的自引分数(SCS)与自我引用分数(SRS) [19]
总结: HCR 的自引和自我引用频率大约是其他两类数学家的两倍。他们的出版数据与其他知名数学家截然不同。除了极少数例外,HCR 这一指标几乎毫无用处,无法识别高质量的数学研究。
3.4 撤稿
在过去,撤稿几乎是个陌生的概念;一旦文章发表,它就被视为“永久存在”,而错误通常通过在同一期刊上发表勘误(errata)来修正。后来,随着出现数据造假的文章,出版社开始撤回这些论文,以防止错误数据继续传播。如今,撤稿被视为科学中必要的终极纠错机制。
和所有科研不端一样,我们所看到的只是冰山一角。截至 2024 年 12 月,Retraction Watch 数据库 [47] 记录了数学作为主要领域的撤稿论文共 1009 篇,而以数学为次要主题的撤稿论文超过 3000 篇。从积极的角度看,撤稿可以作为出版社的一种有效纠错机制;毕竟,错误难免会发生。但若某个期刊或作者有多次撤稿,就合理地引发怀疑:这可能表明存在审稿不严,或者系统性的科研不端行为。
在数据库中,多次出现撤稿的数学期刊大多由 Hindawi 出版(如 Journal of Function Spaces【函数空间杂志】、Mathematical Problems of Engineering【工程中的数学问题】、Complexity【复杂性】)。这在一定程度上与 Hindawi 于 2022 年被 John Wiley & Sons 收购后,出版社试图“清理”旗下期刊、提升质量的举措有关。影响较小的还有 Sciendo Publ(Applied Mathematics and Nonlinear Sciences【应用数学与非线性科学】)以及 MDPI(Symmetry【对称性】、Entropy【熵】)。鉴于撤稿在数学中仍相对少见,将撤稿数据库与数学领域 HCR 名单联系起来尤其有趣。
在 89 位数学领域 HCR 中,有 7 位出现在撤稿数据库里,原因主要包括:涉嫌论文工厂、抄袭或重复发表。
然而,问题并不局限于数学——而且正在迅速恶化。仅在 2023 年,所有学科的撤稿总数超过 1 万篇。按每 10 万篇已发表文章的撤稿率来看,撤稿率最高的国家依次是:沙特阿拉伯、巴基斯坦和中国。从比例上看,被撤稿论文占总发表论文的比例已从 2002 年的 0.02% 上升到 2023 年的 0.2% [29]。
3.5 HCR 与大学排名
大学排名体系在 21 世纪才出现,但它们对大学的声誉和发展产生了巨大影响。虽然我们无法在此展开详尽讨论,但必须强调一点:这些排名完全依赖于可获得的数据,其中很大一部分由商业引文数据库公司提供。换句话说,它们并非基于对研究质量的客观分析。排名体系本身就是一个利润丰厚的产业,大学通常需要支付高额费用来获取排名背后的详细数据。
尤其需要指出的是,上海排名(ARWU, Academic Ranking of World Universities) 依赖 Clarivate 的 HCR 名单。大学的“师资质量”部分包含三类指标:诺贝尔奖、菲尔兹奖,以及 HCR(即 Clarivate 的“顶尖科学家”名单)。
由于 HCR 可能受到操纵,并且这一机制在学术共同体之外鲜为人知,这就为一些国家的大学提供了机会去“购买”HCR,从而提升自己在大学排名中的位置。操作方式是让某位 HCR 宣称与该校存在某种联系(通常是在其个人档案中将该校列为主要隶属机构)。2022 年和 2023 年的一份报告 [44] 提供了详尽分析。
结果可想而知:即使是规模非常小、甚至在国际上几乎没有研究声誉的大学,也突然在全球排名中名列前茅。例如,2023 年在 HCR 数量上排名第 12 的 沙特阿卜杜勒阿齐兹国王大学(King Abdulaziz University, KAU),位列斯坦福大学之前、并列哈佛大学。KAU 在 2000 年时没有任何一位 HCR,到了 2014 年便已超过 100 位。沙特其他大学(如 King Saud University 和 King Abdullah University of Science and Technology)也出现在这一 HCR 操纵网络中。再例如,2014 年排名前 25 的大学中,还包括土耳其的 Hacettepe University(赫捷泰佩大学)和 Malatya University(马拉蒂亚大学)。
在此背景下,Clarivate 在 2023 年完全取消数学领域 HCR 的决定便显得合理。这一领域的研究者人数较少,因此其指标更容易受到少数人的严重操纵。
3.6 本节小结
在前几节中,我们描述了 Clarivate 关于高被引学者(HCR)的分析,以及他们在 2023 年将数学领域从 HCR 名单中彻底剔除的决定。我们提供了实证证据,显示 HCR 这一指标并不能识别出杰出的数学研究。
我们还看到:在 HCR 名单中出现的大量问题,最终对大学排名产生了深远影响。由于大学排名与政治议程、公共资金和大学领导层的目标紧密相连,这一事实凸显了问题的严重性。
最后,我们强调:欺诈性出版现象并非数学独有,而是科学整体的问题,它正不断侵蚀着科研的完整性和公众对科学的信任。
4 数学领域中欺诈性出版的多重表现
文献计量学(Bibliometrics)是一种试图量化科学成果质量的工具。在数学科学中,最重要的学术欺诈形式很可能就是文献计量学操纵。下面我们将更详细地讨论这些问题。
最为普遍的科研不端行为是偶发性的失范行为。它通常只能被同行专家识别,不会被认可,但也常因被视为“影响不大”或难以追究而不了了之。这可以称为“偶发性不良实践区”。其中包括以下行为:
- 将一篇完整的研究拆分成多个最小可发表单元(俗称“香肠切片”),而不是形成一篇更实质性的论文;
- 夸大的、但仍(或多或少)可容忍的自引数量,或引用数学圈中好友的论文;
- 重复利用以前写过的文本段落,例如对研究领域的标准性引言(如今大多数期刊都会使用相似性检测工具,通常能发现这些情况);
- 对已有成果的引用不诚实或不严谨(夸大自己的贡献,刻意“遗忘”与自己内容相近的论文,用教科书替代引用原始论文……);
- 对已有文献的核查草率;
- 审稿人要求作者引用审稿人自己的文章。
但正如 D. Docampo 在 [18] 中所说:“……在复杂的现代学术环境中,‘发表或灭亡’这一格言正逐渐演变为另一种口号:‘要想不被边缘化,就必须获得引用’。(……) 引用的重要性已驱动出一种全新的欺骗形式:隐秘网络,用于操纵引用。”
这可以称为“系统性不良实践区”,其中包括:
- 引用操纵,例如 [6] 中记录的情况:通过插入无意义的文本并固定一组参考文献,或在同行评审过程中添加参考文献来操纵引用;
- 编辑要求作者在论文接受后必须增加对本刊其他文章的引用,作为发表的条件;
- 翻译抄袭或“复制粘贴”式剽窃;
- 学术上级声称合著,而他们实际上并未对论文有贡献,或以其他方式影响署名归属;
- 故意提供错误的作者单位信息;
- 在未获得同意的情况下将他人列为作者;
- 提供虚假的资助信息。虽然数学中因产业资助导致的利益冲突较为罕见,但有时会通过虚假的资助信息来暗示研究“高质量”;
- 掠夺性会议作为引文联盟的一部分。
不幸的是,当涉及金钱、科研声誉甚至就业前景,或者当不端行为需要投入大量“犯罪能量”时,就会出现一个新的层次:欺诈行为区。
著名科研打假人士 Nick Wise 在 Retraction Watch 博客上说:“如今有一个完整的经济体系,一个由 Facebook 群组、WhatsApp 群组、Telegram 频道构成的生态系统,在里面贩卖论文作者署名、引用、书籍章节,甚至专利作者署名。”
以下是一些例子:
引用买卖:专业引用中介(通常使用匿名邮箱)提供一份需要引用的论文清单,并为引用者提供“感谢费”;
论文工厂:这一点几乎不言自明——从职业代笔人手里购买论文,再署上自己的名字,是严重的科研欺诈 [11];
作者身份买卖:论文工厂可以通过在一篇已准备发表的论文中出售作者署名来增加收益(或降低买家的费用);
勒索:已有多起勒索案例被记录。例如,论文工厂威胁作者称,如果不给钱,就会将其科研不端行为举报给期刊、雇主或资助机构;
权力滥用:对“不服从”的研究人员进行打压,通常由资深学者实施。近年来,媒体频频报道顶尖学术机构的领导因霸凌而被迫辞职;
身份欺诈:多起案例显示,掠夺性期刊在未经同意的情况下,将研究人员列为编辑,有时即便在当事人投诉后也拒绝删除其名字;
抄袭论文并篡改日期,使其看起来像是原始成果;
使用化名发表论文,例如为了避免与此前的不端行为关联;
未披露严重的利益冲突;
创建与知名学者极为相似的邮箱账号,并推荐他们作为审稿人,从而审自己的论文。
欺诈行为很少会真正进入司法程序。少数例外之一是总部位于印度的 OMICS Group Inc。该公司建立了一个复杂的掠夺性期刊和会议网络(约 700 本期刊,其中一些短命、频繁改名;每年约 3000 场会议)。2016 年,美国联邦贸易委员会(FTC)对 OMICS 提起诉讼。2022 年 5 月的最终判决 [41] 认定该公司使用了“欺骗性市场行为”,并详细记录了上述许多欺诈手法。尽管其名字显示与生命科学相关,但该公司也出版多本数学期刊。
5 结语:关于 AI 的几点话
尽管人工智能(AI)在许多任务中是一种极其有价值的工具,但它也带来了新的风险和挑战,而科研共同体才刚刚开始理解这些问题。
大多数期刊编辑和出版商一致认为,作者可以使用 AI 工具(如 DeepL、ChatGPT 或 DeepSeek)来进行文字润色和校对。这种做法对非英语母语者尤其有帮助。然而,至关重要的是,作者必须对其论文内容负责,确保出版物中的内容(包括引文、表格和图像)不会因自动化翻译或编辑而被篡改。在正常情况下,使用这些 AI 服务进行文字校对并不需要在文章中正式致谢。相比之下,当 AI 被用于更实质性的任务——例如生成或解读研究内容时——许多出版商现在要求作者明确披露这种使用方式,并且任何 AI 都不能被列为合著者。政策的这一转变凸显出一个日益增长的担忧:AI 生成的文本可能被用于捏造或不当篡改科学结论,从而破坏科研诚信。文献 [22] 的附录提供了一个有价值的资料汇编,收录了全球各出版商和科研机构的 AI 政策声明,展示了在上述关键原则上的某种趋同。
复杂 AI 语言模型的出现,使得制造虚假研究变得更便宜、更容易。论文工厂很可能利用 AI,在几乎没有人工监督的情况下生成看似合理的文本 [28]。这同时也为欺诈检测带来了重大挑战:随着 AI 生成文本变得越来越连贯、越来越符合上下文,传统筛查方法越来越难以将其与人类写作区分开来。这推动了对新型“诚信软件”的投资——即正在开发的 AI 工具,用于捕捉自动化内容生成的迹象。然而,这几乎必然会导致一场“军备竞赛”:随着检测工具的改进,生成模型也会不断进化,从而可能形成双方永无止境的创新循环。
目前,不寻常或别扭的语言结构(即所谓 tortured phrases)仍是识别 AI 生成文本的常见警示信号 [9](见表 3)。然而,单纯依赖语言异常并不可持续,因为随着 AI 模型愈加精细,这些痕迹将逐渐消失。因此,学界呼吁制定健全的指导方针,建立欺诈性论文的共享数据库,并为检测工具和编辑流程制定透明的规范。
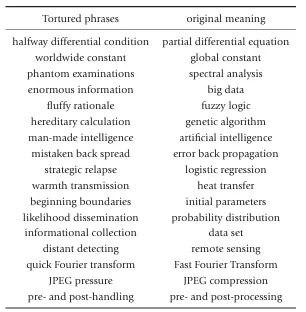
表 3. “拷打短语”(Tortured phrases)汇编
一个重要的转折点是 Wiley 与 Hindawi 的经历,据报道,公司在处理欺诈性投稿时耗费了大量资源。随后,Wiley 宣布启动一项“AI 驱动的论文工厂检测”试点服务。其他主要出版商(如 Springer)也紧随其后,寻求综合性策略,将算法检测、专家审查和社区举报结合起来。在他对科学出版物中未披露 AI 使用情况的最新调查中 [22],研究者 Alex Glynn 得出结论:“这项分析[…]表明问题已相当普遍,渗透到了备受尊重的出版商旗下的期刊和会议论文集。”
除了出版商之外,资助机构也开始发布 AI 相关指南。例如,美国国家科学基金会(NSF)已发布声明,强调在 AI 使用中保持透明的重要性,并提出负责任的使用要求,其中包括禁止“将任何来自科研申请、评审信息和相关记录的内容上传到未经批准的生成式 AI 工具”[44]。这引出了一个更为根本的问题:如果大型语言模型(LLMs)在训练过程中使用了我们的论文——无论是否经过我们同意——这对数学共同体意味着什么 [46]。
总结来说:AI 将加剧科学出版中已存在的问题,并使作弊的方式倍增。科研共同体是否拥有足够的资源来应对这些问题,仍有待观察。在此期间,我们呼吁每个人都应当为加强所在领域的学术伦理标准而努力,并在这场不平等的斗争中支持诚实的科学家。
附录A. 术语表
Citation cartel(引文联盟):一群人约定互相引用联盟成员及其偏好的期刊,不论这些文献是否与他们的工作真正相关。
Citation broker(引用中介):通过匿名邮箱联系,提供一份需要引用的文章清单,并为每一次引用支付一笔“感谢费”。付款通常通过加密货币进行。
Citejacked journal(被“引用劫持”的期刊):正规期刊引用了被“劫持期刊”(Hijacked journal, v1)上的文章。
Mega-journal(巨型期刊):每年发表海量文章的期刊;在开放获取(Open Access)出现之前,这类期刊并不存在。最具代表性的巨型出版商之一是总部位于瑞士巴塞尔的 MDPI,目前旗下拥有 433 本期刊。其旗舰期刊 International Journal of Environmental Research and Public Health(《国际环境研究与公共卫生杂志》)每年发表近 17,000 篇论文(该期刊已于 2023 年被 Web of Science 剔除,因此将失去影响因子 [7])。其最大的数学期刊 Mathematics 拥有超过 1000 名编委(其中 27 人是高被引研究人员 HCR),并在 2023 年发表了超过 6000 篇文章——相比之下,zbMath 在同一年仅审阅了约 120,000 篇数学论文。其年收入估计约为 1000 万瑞士法郎。多起丑闻与撤稿事件表明,在如此庞大的发文量中保持高水平的科学质量是不可能的(参见 [38];这也再次说明质量低劣的文章是如何进入新闻报道的)。
Hijacked journal, v1(劫持期刊,版本 1):假冒网站,使用现有正规期刊的标题、ISSN 和元数据。这类骗局大约出现在 2010 年,与“引用劫持期刊”密切相关。目前已记录约 250 起案例,其中没有涉及数学;最近 Springer Nature 和 Elsevier 旗下的期刊也成为目标。一项最新研究显示,大约 66% 的“劫持期刊”论文存在抄袭证据 [4]。
Hijacked journal, v2(劫持期刊,版本 2):其编委会被引文联盟成员接管或渗透的期刊。有时,这些期刊会永久性地转变为掠夺性期刊。
Paper mill(论文工厂):以商业目的为研究人员、学者和学生大规模生产和销售论文的机构,用于发表在同行评审期刊中。许多论文工厂的论文包含捏造的数据 [11]。关于某一俄罗斯论文工厂的详细分析见 [3]。
Predatory journal(掠夺性期刊):利用开放获取出版模式欺骗作者支付费用的期刊。这类出版商经常虚报期刊的影响因子,缺乏编辑标准,并谎称提供严格的同行评审过程。一个著名的例子是期刊 Advances in Difference Equations(《差分方程进展》);zbMath 的数据清楚地揭示了其中存在强烈的引文联盟。经过多次续办失败后,SpringerNature 决定关闭该刊,最后一篇论文发表于 2021 年。目前并没有一份正式的“掠夺性期刊名单”;然而,有关这一问题的建议可见 [43]。
Predatory conference(掠夺性会议):缺乏或几乎没有报告同行评审的会议,组织混乱,核心目的在于为主办方赚钱。这类会议通常在大型会场举办,但现场几乎无人参加。它们往往强调虚拟参会选项,并承诺会后在知名引文数据库收录的刊物上发表。
Scientific Sleuth(科研侦探):在科学文献中寻找问题的人,通常利用业余时间进行。
Tortured phrases(拷打短语):错误的科学词汇,通常源自机器翻译 / 改写 / 文本生成 [9, 10]。它们是“问题论文筛查器”(Problematic Paper Screener)所使用的识别指标 [45]。一份从数学和数据科学论文中收集的“拷打短语”汇编(这些论文由“问题论文筛查器”标记)可见表 3。
References
[1] Robert Adler, John Ewing, and Peter Taylor, Citation statistics: a report from the International Mathematical Union (IMU) in cooperation with the International Council of Industrial and Applied Mathematics (ICIAM) and the Institute of Mathematical Statistics (IMS), Statist. Sci. 24 (2009), no. 1,1–14, DOI 10.1214/09-STS285. MR2561120
[2] Ilka Agricola, Lynn Heller, Wil Schilders, Moritz Schubotz, Peter Taylor, and Luis Vega, Fraudulent Publishing in the Mathematical Sciences, digital version with all references, 2025, https://arxiv.org/abs/2509.07257.
[3] Anna Albakina, Publication and collaboration anomalies in academic papers originating from a paper mill: Evidence from a Russia-based paper mill, Learned Publishing (2023), 689–702, https://doi.org/10.1002/leap.1574.
[4] Anna Albakina, Prevalence of plagiarism in hijacked journals: A text similarity analysis, Accountability in Research, 2024, https://doi.org/10.1080/08989621.2024.2387210.
[5] Mario Biagioli and Alexandra Lippman (eds.), Gaming the Metrics: Misconduct and Manipulation in Academic Research, The MIT Press, 2020 (OA), https://doi.org/10.7551/mitpress/11087.001.0001.
[6] Lonni Besan¸con, Guillaume Cabanac, Cyril Labb´e, and Alexander Magazinov, Sneaked references: Fabricated reference metadata distort citation counts, J. Assoc. Inf. Sci. Technol. 75 (2024), no. 12, 1368–1379, https://doi.org/10.1002/asi.24896.
[7] Jeffrey Brainard, Fast-growing open-access journals lose impact factors, Science 379 (2023), no. 6639, 1283–1284, https://doi.org/10.1126/science.adi0098.
[8] Jennifer A. Byrne, Yasunori Park, Reese A.K. Richardson, Pranujan Pathmendra, Mengyi Sun, and Thomas Stoeger, Protection of the human gene research literature from contract cheating organizations known as research paper mills, Nucleic Acids Research 50 (2022), 12058–12070, https://doi.org/10.1093/nar/gkac1139.
[9] Guillaume Cabanac, Chain retraction: how to stop bad science propagating through the literature, Nature 632 (2024), 977–979, https://doi.org/10.1038/d41586-024-02747-1.
[10] Guillaume Cabanac, Cyril Labb´e, and Alexander Magazinov, Tortured phrases: A dubious writing style emerging inscience. Evidence of critical issues affecting established journals, 2021, https://arxiv.org/pdf/2107.06751.
[11] C. Candal-Pedreira, J. S. Ross, A. Ruano-Ravina, D.S. Egilman, E. Fern´andez, and M. P´erez-R´ıos, Retracted papers originating from paper mills: cross sectional study, BMJ 379 (2022), e071517, https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9703783/.
[12] Alan Carey, Michael G. Cowling, and Peter Taylor, Assessing research in the mathematical sciences, Gazette of the Australian Mathematical Society 34 (2007), no. 2.
[13] Minal Caron, Carolin Lye, Barbara Bierer, and Mark Barnes, The PubPeer conundrum: Administrative challenges in research misconduct proceedings, Accountability in Research (2024), 1–19, https://doi.org/10.1080/08989621.2024.2390007.
[14] Michele Catanzaro, Citation cartels help some mathematicians—and their universities—climb the rankings, Science, 30 Jan. 2024, https://doi.org/10.1126/science.zcl2s6d.
[15] Lauranne Chaignon, Highly Cited Researchers: anatomy of a list, Quantitative Science Studies 6 (2025), 305–327, https://doi.org/10.1162/qss_a_00351.
[16] Dalmeet Singh Chawla, Hundreds of ‘predatory’ journals indexed on leading scholarly database, Nature News article, 8 February 2021, https://doi.org/10.1038/d41586-021-00239-0.
[17] Farshid Danesh and Ali Mardani-Nejad, A Historical Overview of Bibliometrics, in: Handbook Bibliometrics, ed. Rafael Ball, De Gruyter, 2021, https://doi.org/10.1515/9783110646610-003.
[18] Domingo Docampo, The dark world of ‘citation cartels’: Predatory journals and bad faith scholars are gaming the system—at scale, The Chronicle of Higher Education, March 6, 2024, https://www.chronicle.com/article/the-dark-world-of-citation-cartels.
[19] Edward Dunne, Don’t count on it, Notices Amer. Math. Soc. 68 (2021), no. 1, 114–118. MR4658679
[20] Erik von Elm, Greta Poglia, Bernhard Walder, and Martin R. Tramèr, Different patterns of duplicate publication: An Analysis of articles used in systematic reviews, JAMA 291 (2004), no. 8, 974–980, https://doi.org/10.1001/jama.291.8.974.
[21] Susan A. Elmore and Eleanor H. Weston, Predatory Journals: What They Are and How to Avoid Them, Toxicol. Pathol. 48 (2020), no. 4, 607–610, https://doi.org/10.1177/0192623320920209.
[22] Alex Glynn, Suspected Undeclared Use of Artificial Intelligence in the Academic Literature: An Analysis of the Academ-AI Dataset, 2024, https://arxiv.org/abs/2411.15218.
[23] Benoît Godin, On the origins of bibliometrics, Scientometrics 68 (2006), 109–133, https://doi.org/10.1007/s11192-006-0086-0.
[24] Klaus Hulek and Olaf Teschke, How do mathematicians publish?—Some trends, Eur. Math. Soc. Mag. 129 (2023), 36–41, https://doi.org/10.4171/MAG/160.
[25] Hazem Ibrahim, Fengyuan Liu, Yasir Zaki, and Talal Rahwan, Citation manipulation through citation mills and pre-print servers, Sci. Rep. 15 (2025), 5480, https://doi.org/10.1038/s41598-025-88709-7.
[26] V´ıt Mach ´aˇcek and Martin Srholec, Predatory publishing in Scopus: Evidence on cross-country differences, Quantitative Science Studies 3 (2022), 859–887, https://doi.org/10.1162/qss_a_00213.
[27] Stuart Macdonald and Jacqueline Kam, Aardvark et al.: quality journals and gamesmanship in management studies, Journal of Information Science 33 (2007), no. 6, https://doi.org/10.1177/0165551507077419.
[28] Layal Liverpool, AI intensifies fight against ‘paper mills’ that churn out fake research, Nature News, May 2023, https:// www.nature.com/articles/d41586-023-01780-w.
[29] Richard Van Noorden, More than 10,000 research papers were retracted in 2023—a new record, Nature 624 (2023), 479–481, https://doi.org/10.1038/d41586-023-03974-8.
[30] Martin Szomszor, David A. Pendlebury, and Jonathan Adams, How much is too much? The difference between research influence and self-citation excess, Scientometrics 123 (2020), 11191147, https://doi.org/10.1007/s11192-020-03417-5.
[31] Ivan Oransky and Adam Marcus, There’s far more scientific fraud than anyone wants to admit, The Guardian, August 9, 2023, https://tinyurl.com/mruef5ku.
[32] David A. Pendlebury, White Paper: using bibliometrics in evaluating research, Thomson Reuters, Philadelphia, 2008.
[33] David A. Pendlebury, Highly Cited Researchers 2023: The evolution of our evaluation and selection policy to support a robust scholarly landscape, blog entry, Nov. 15, 2023, https://tinyurl.com/yn355s5f.
[34] David A. Pendlebury, Citations and stature: Not so simpleanymore, blog entry, Nov. 19, 2024, https://clarivate.com/academia-government/blog/citations-and-stature-not-so-simple-anymore/.
[35] Vicente Saf ´on, Domingo Docampo, and Lawrence Cram, Screening articles by citation reputation, Quantitative Science Studies (2025), https://doi.org/10.1162/qss_a_00355.
[36] Marilyn Strathern, ‘Improving ratings’: audit in the British University system, European Review 5 (1997), no. 3, 305–321.
[37] Alexander Yong, Critique of Hirsch’s citation index: a combinatorial Fermi problem, Notices Amer. Math. Soc. 61 (2014), no. 9, 1040–1050, DOI 10.1090/noti1164. MR3241560
[38] BishopBlog, Collapse of scientific standards at MDPI journals: a case study, July 2024, https://deevybee.blogspot.com/2024/07/collapse-of-scientific-standards-at.html.
[39] Clarivate, History of citation indexing (not dated/signed), https://clarivate.com/webofsciencegroup/essays/history-of-citation-indexing/.
[40] Clarivate, HCRs from past years, https://clarivate.com/highly-cited-researchers/past-lists/.
[41] Federal Trade Commission, Case 2:16-cv-02022-GMNVCF, Document 86, FTC’s motion for summary judgment and memorandum in support thereof, May 2022, https://www.ftc.gov/system/files/documents/cases/omics_de_86_-_ftc_motion_for_summary_judgment.pdf.
[42] IMU Committee on Permissions, Ensuring widespread and equitable access to back issues of mathematics journals, Report, June 2024, https://www.mathunion.org/fileadmin/IMU/Report/2024-IMU_Committee_on_Permissions-FinalReport.pdf.
[43] IMU-ICIAM joint statement & recommendations, How to Fight Fraudulent Publishing in the mathematical sciences, 2025.
[44] National Science Foundation, Notice to research community: Use of generative artificial intelligence technology in the NSF merit review process, December 2023, https://new.nsf.gov/news/notice-to-the-research-community-on-ai?ref=exo-insight.ghost.io.
[45] The Problematic Paper Screener, https://www.irit.fr/~Guillaume.Cabanac/problematic-paper-screener/.
[46] Michael Harris, The Silicon Reckoner: What computers will do for, or to, mathematics and mathematicians, blog, https://siliconreckoner.substack.com.
[47] Retraction Watch Blog, Category: math retractions (updated regularly), https://tinyurl.com/2papjbps. Robert Adler, John Ewing, and Peter Taylor, Citation statistics: a report from the International Mathematical Union (IMU) in cooperation with the International Council of Industrial and Applied Mathematics (ICIAM) and the Institute of Mathematical Statistics (IMS), Statist. Sci. 24 (2009), no. 1,1–14, DOI 10.1214/09-STS285. MR2561120
[2] Ilka Agricola, Lynn Heller, Wil Schilders, Moritz Schubotz, Peter Taylor, and Luis Vega, Fraudulent Publishing in the Mathematical Sciences, digital version with all references, 2025, https://arxiv.org/abs/2509.07257.
[3] Anna Albakina, Publication and collaboration anomalies in academic papers originating from a paper mill: Evidence from a Russia-based paper mill, Learned Publishing (2023), 689–702, https://doi.org/10.1002/leap.1574.
[4] Anna Albakina, Prevalence of plagiarism in hijacked journals: A text similarity analysis, Accountability in Research, 2024, https://doi.org/10.1080/08989621.2024.2387210.
[5] Mario Biagioli and Alexandra Lippman (eds.), Gaming the Metrics: Misconduct and Manipulation in Academic Research, The MIT Press, 2020 (OA), https://doi.org/10.7551/mitpress/11087.001.0001.
[6] Lonni Besan¸con, Guillaume Cabanac, Cyril Labb´e, and Alexander Magazinov, Sneaked references: Fabricated reference metadata distort citation counts, J. Assoc. Inf. Sci. Technol. 75 (2024), no. 12, 1368–1379, https://doi.org/10.1002/asi.24896.
[7] Jeffrey Brainard, Fast-growing open-access journals lose impact factors, Science 379 (2023), no. 6639, 1283–1284, https://doi.org/10.1126/science.adi0098.
[8] Jennifer A. Byrne, Yasunori Park, Reese A.K. Richardson, Pranujan Pathmendra, Mengyi Sun, and Thomas Stoeger, Protection of the human gene research literature from contract cheating organizations known as research paper mills, Nucleic Acids Research 50 (2022), 12058–12070, https://doi.org/10.1093/nar/gkac1139.
[9] Guillaume Cabanac, Chain retraction: how to stop bad science propagating through the literature, Nature 632 (2024), 977–979, https://doi.org/10.1038/d41586-024-02747-1.
[10] Guillaume Cabanac, Cyril Labb´e, and Alexander Magazinov, Tortured phrases: A dubious writing style emerging inscience. Evidence of critical issues affecting established journals, 2021, https://arxiv.org/pdf/2107.06751.
[11] C. Candal-Pedreira, J. S. Ross, A. Ruano-Ravina, D.S. Egilman, E. Fern´andez, and M. P´erez-R´ıos, Retracted papers originating from paper mills: cross sectional study, BMJ 379 (2022), e071517, https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9703783/.
[12] Alan Carey, Michael G. Cowling, and Peter Taylor, Assessing research in the mathematical sciences, Gazette of the Australian Mathematical Society 34 (2007), no. 2.
[13] Minal Caron, Carolin Lye, Barbara Bierer, and Mark Barnes, The PubPeer conundrum: Administrative challenges in research misconduct proceedings, Accountability in Research (2024), 1–19, https://doi.org/10.1080/08989621.2024.2390007.
[14] Michele Catanzaro, Citation cartels help some mathematicians—and their universities—climb the rankings, Science, 30 Jan. 2024, https://doi.org/10.1126/science.zcl2s6d.
[15] Lauranne Chaignon, Highly Cited Researchers: anatomy of a list, Quantitative Science Studies 6 (2025), 305–327, https://doi.org/10.1162/qss_a_00351.
[16] Dalmeet Singh Chawla, Hundreds of ‘predatory’ journals indexed on leading scholarly database, Nature News article, 8 February 2021, https://doi.org/10.1038/d41586-021-00239-0.
[17] Farshid Danesh and Ali Mardani-Nejad, A Historical Overview of Bibliometrics, in: Handbook Bibliometrics, ed. Rafael Ball, De Gruyter, 2021, https://doi.org/10.1515/9783110646610-003.
[18] Domingo Docampo, The dark world of ‘citation cartels’: Predatory journals and bad faith scholars are gaming the system—at scale, The Chronicle of Higher Education, March 6, 2024, https://www.chronicle.com/article/the-dark-world-of-citation-cartels.
[19] Edward Dunne, Don’t count on it, Notices Amer. Math. Soc. 68 (2021), no. 1, 114–118. MR4658679
[20] Erik von Elm, Greta Poglia, Bernhard Walder, and Martin R. Tramèr, Different patterns of duplicate publication: An Analysis of articles used in systematic reviews, JAMA 291 (2004), no. 8, 974–980, https://doi.org/10.1001/jama.291.8.974.
[21] Susan A. Elmore and Eleanor H. Weston, Predatory Journals: What They Are and How to Avoid Them, Toxicol. Pathol. 48 (2020), no. 4, 607–610, https://doi.org/10.1177/0192623320920209.
[22] Alex Glynn, Suspected Undeclared Use of Artificial Intelligence in the Academic Literature: An Analysis of the Academ-AI Dataset, 2024, https://arxiv.org/abs/2411.15218.
[23] Benoît Godin, On the origins of bibliometrics, Scientometrics 68 (2006), 109–133, https://doi.org/10.1007/s11192-006-0086-0.
[24] Klaus Hulek and Olaf Teschke, How do mathematicians publish?—Some trends, Eur. Math. Soc. Mag. 129 (2023), 36–41, https://doi.org/10.4171/MAG/160.
[25] Hazem Ibrahim, Fengyuan Liu, Yasir Zaki, and Talal Rahwan, Citation manipulation through citation mills and pre-print servers, Sci. Rep. 15 (2025), 5480, https://doi.org/10.1038/s41598-025-88709-7.
[26] V´ıt Mach ´aˇcek and Martin Srholec, Predatory publishing in Scopus: Evidence on cross-country differences, Quantitative Science Studies 3 (2022), 859–887, https://doi.org/10.1162/qss_a_00213.
[27] Stuart Macdonald and Jacqueline Kam, Aardvark et al.: quality journals and gamesmanship in management studies, Journal of Information Science 33 (2007), no. 6, https://doi.org/10.1177/0165551507077419.
[28] Layal Liverpool, AI intensifies fight against ‘paper mills’ that churn out fake research, Nature News, May 2023, https:// www.nature.com/articles/d41586-023-01780-w.
[29] Richard Van Noorden, More than 10,000 research papers were retracted in 2023—a new record, Nature 624 (2023), 479–481, https://doi.org/10.1038/d41586-023-03974-8.
[30] Martin Szomszor, David A. Pendlebury, and Jonathan Adams, How much is too much? The difference between research influence and self-citation excess, Scientometrics 123 (2020), 11191147, https://doi.org/10.1007/s11192-020-03417-5.
[31] Ivan Oransky and Adam Marcus, There’s far more scientific fraud than anyone wants to admit, The Guardian, August 9, 2023, https://tinyurl.com/mruef5ku.
[32] David A. Pendlebury, White Paper: using bibliometrics in evaluating research, Thomson Reuters, Philadelphia, 2008.
[33] David A. Pendlebury, Highly Cited Researchers 2023: The evolution of our evaluation and selection policy to support a robust scholarly landscape, blog entry, Nov. 15, 2023, https://tinyurl.com/yn355s5f.
[34] David A. Pendlebury, Citations and stature: Not so simpleanymore, blog entry, Nov. 19, 2024, https://clarivate.com/academia-government/blog/citations-and-stature-not-so-simple-anymore/.
[35] Vicente Saf ´on, Domingo Docampo, and Lawrence Cram, Screening articles by citation reputation, Quantitative Science Studies (2025), https://doi.org/10.1162/qss_a_00355.
[36] Marilyn Strathern, ‘Improving ratings’: audit in the British University system, European Review 5 (1997), no. 3, 305–321.
[37] Alexander Yong, Critique of Hirsch’s citation index: a combinatorial Fermi problem, Notices Amer. Math. Soc. 61 (2014), no. 9, 1040–1050, DOI 10.1090/noti1164. MR3241560
[38] BishopBlog, Collapse of scientific standards at MDPI journals: a case study, July 2024, https://deevybee.blogspot.com/2024/07/collapse-of-scientific-standards-at.html.
[39] Clarivate, History of citation indexing (not dated/signed), https://clarivate.com/webofsciencegroup/essays/history-of-citation-indexing/.
[40] Clarivate, HCRs from past years, https://clarivate.com/highly-cited-researchers/past-lists/.
[41] Federal Trade Commission, Case 2:16-cv-02022-GMNVCF, Document 86, FTC’s motion for summary judgment and memorandum in support thereof, May 2022, https://www.ftc.gov/system/files/documents/cases/omics_de_86_-_ftc_motion_for_summary_judgment.pdf.
[42] IMU Committee on Permissions, Ensuring widespread and equitable access to back issues of mathematics journals, Report, June 2024, https://www.mathunion.org/fileadmin/IMU/Report/2024-IMU_Committee_on_Permissions-FinalReport.pdf.
[43] IMU-ICIAM joint statement & recommendations, How to Fight Fraudulent Publishing in the mathematical sciences, 2025.
[44] National Science Foundation, Notice to research community: Use of generative artificial intelligence technology in the NSF merit review process, December 2023, https://new.nsf.gov/news/notice-to-the-research-community-on-ai?ref=exo-insight.ghost.io.
[45] The Problematic Paper Screener, https://www.irit.fr/~Guillaume.Cabanac/problematic-paper-screener/.
[46] Michael Harris, The Silicon Reckoner: What computers will do for, or to, mathematics and mathematicians, blog, https://siliconreckoner.substack.com.
[47] Retraction Watch Blog, Category: math retractions (updated regularly), https://tinyurl.com/2papjbps.
Original link: https://www.ams.org/journals/notices/202509/rnoti-p1038.pdf